
AI compute refers to the specialized computational resources, infrastructure, and processing power required to train, develop, and deploy artificial intelligence systems. It encompasses everything from the hardware that runs AI algorithms to the energy and cooling systems that keep that hardware functioning.
The story of modern AI is inseparable from the story of computational power. While many of today's fundamental AI algorithms were developed decades ago, they remained theoretical curiosities until computing power caught up with their demands. The deep learning revolution that began around 2012 wasn't driven primarily by new algorithms, but by the availability of graphics processing units (GPUs) that could handle the massive parallel computations required (OpenAI, 2023).
This computational foundation continues to shape what's possible in AI development. From the specialized chips powering your smartphone's voice assistant to the warehouse-sized data centers training the latest large language models, AI compute determines both the capabilities and limitations of artificial intelligence systems.
The Exponential Growth Challenge
The computational demands of cutting-edge AI have been growing at a staggering pace. Between 2012 and 2023, the amount of compute used to train the largest AI models increased by a factor of over 10 million - doubling approximately every 3.4 months (Epoch AI, 2023). This growth rate far exceeds Moore's Law, which historically described a doubling of computing power roughly every two years.
This exponential trajectory creates both opportunities and challenges. On one hand, it has enabled AI capabilities that seemed impossible just a few years ago, from generating photorealistic images to writing coherent essays. On the other hand, it has concentrated AI development among organizations with access to massive computational resources, raising concerns about accessibility and democratization.
The computational requirements for state-of-the-art AI systems have become so substantial that they're measured in terms previously reserved for supercomputers. Training a single large language model can consume millions of GPU-hours and cost tens of millions of dollars in computing resources alone. This scale of computation generates significant heat, requires specialized cooling systems, and consumes enough electricity to power small towns.
The environmental impact of this computational demand has become a growing concern. Training a single large AI model can generate carbon emissions equivalent to the lifetime emissions of five average American cars. As AI systems continue to grow in size and complexity, finding ways to make AI computation more efficient and sustainable has become an urgent priority for the field.
The Hardware Evolution
The computational backbone of AI has evolved dramatically over the past decade, driven by the unique demands of machine learning workloads. Traditional central processing units (CPUs) proved inadequate for the massive parallel computations required by neural networks, leading to the adoption of graphics processing units (GPUs) originally designed for video games and graphics rendering (NVIDIA, 2023).
| Hardware Type | Key Strengths | Limitations | Typical Applications | Energy Efficiency |
|---|---|---|---|---|
| CPUs | Flexibility, complex logic, legacy support | Limited parallelism, higher latency | Small models, inference, preprocessing | Low |
| GPUs | Massive parallelism, mature ecosystem | High power consumption, cost | Training large models, batch inference | Medium |
| TPUs | Optimized for ML workloads, high throughput | Less flexible, vendor lock-in | Training and serving at scale | High |
| FPGAs | Reconfigurable, customizable | Complex programming, higher latency | Specialized inference, prototyping | Medium-High |
| ASICs | Maximum efficiency for specific tasks | Fixed functionality, high development cost | Edge devices, specialized applications | Very High |
| Neuromorphic | Event-driven processing, brain-inspired | Emerging technology, limited software | Research, sparse/temporal processing | Potentially Very High |
GPUs excel at performing many simple calculations simultaneously - exactly what's needed for the matrix multiplications that form the core of neural network training and inference. NVIDIA, originally a gaming hardware company, has become one of the most valuable companies in the world largely due to the adoption of their GPUs for AI workloads.
As AI's computational demands have continued to grow, even more specialized hardware has emerged. Tensor Processing Units (TPUs) developed by Google are custom-designed chips optimized specifically for machine learning workloads. These application-specific integrated circuits (ASICs) sacrifice the flexibility of general-purpose processors for dramatically improved efficiency on AI tasks (Google Cloud, 2023).
The hardware landscape continues to diversify with neuromorphic chips that mimic the structure of biological brains, field-programmable gate arrays (FPGAs) that can be reconfigured for specific workloads, and a growing ecosystem of AI accelerators from companies like Intel, AMD, and numerous startups. Each hardware approach offers different trade-offs between performance, energy efficiency, flexibility, and cost.
The most powerful AI systems now use specialized data centers with thousands of interconnected processors working in parallel. These systems require not just raw computational power but sophisticated networking infrastructure to coordinate between processors, high-speed memory systems to feed data to the processors, and advanced cooling systems to manage the enormous heat generated.
The Training-Inference Divide
AI computation falls into two fundamentally different categories with distinct requirements and constraints: training and inference. Training involves building the AI model by showing it examples and adjusting its parameters, while inference is using the trained model to make predictions or decisions on new data (AWS, 2023).
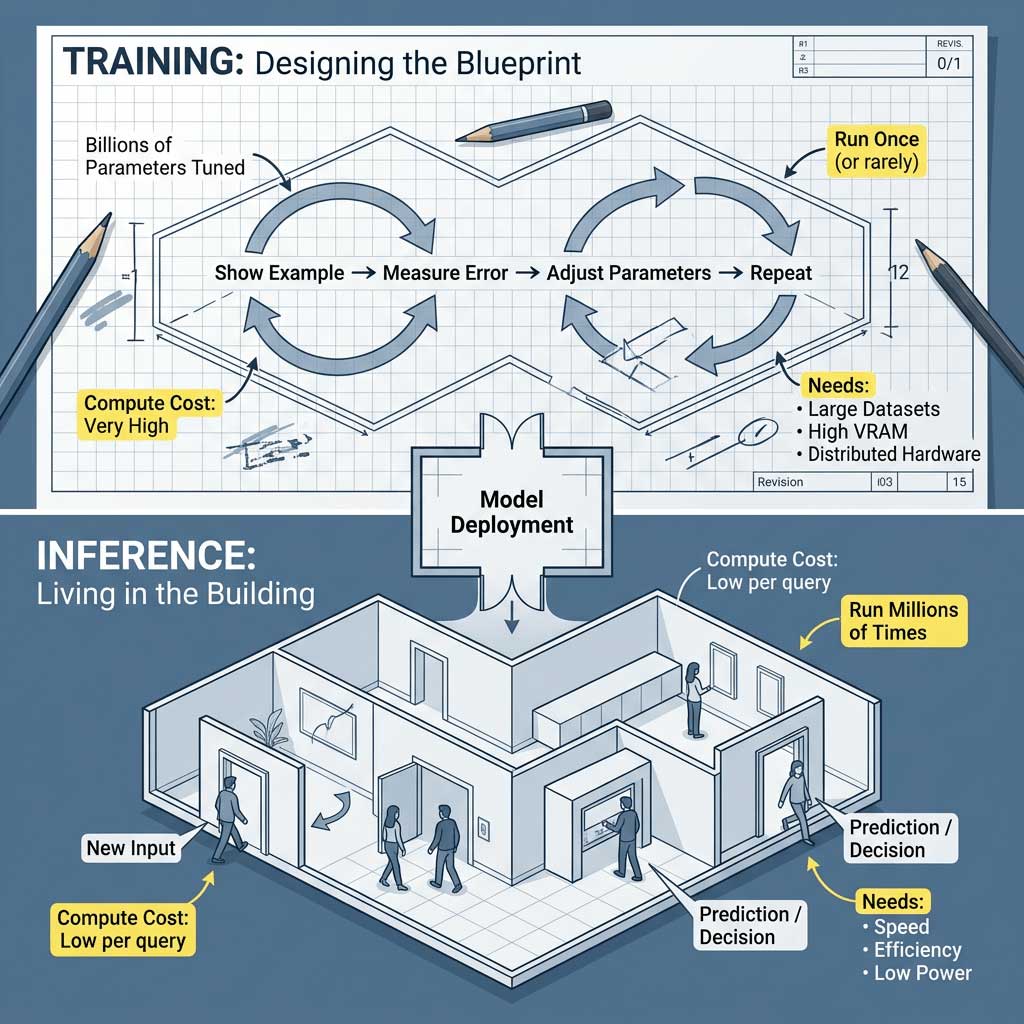
Training is typically the more computationally intensive phase, often requiring days or weeks of continuous processing on multiple high-end GPUs or specialized hardware. It's characterized by massive batch processing, where the system analyzes many examples simultaneously to update the model parameters. Training workloads are often run in data centers with access to vast computational resources, high-speed networking, and specialized cooling systems.
Inference, by contrast, often needs to happen in real-time and on a wide variety of hardware, from powerful servers to resource-constrained mobile devices. While individual inference operations require far less computation than training, they may need to be performed billions of times per day in production systems, making efficiency crucial. Inference workloads are also more likely to have strict latency requirements - a voice assistant that takes 30 seconds to respond isn't very useful, regardless of its accuracy.
This divide has led to different optimization strategies and even different hardware designs for training versus inference. Training systems prioritize raw computational throughput and are willing to sacrifice some efficiency to achieve it. Inference systems, particularly those deployed on edge devices like phones or IoT sensors, prioritize energy efficiency, low latency, and minimal memory usage.
The gap between training and inference requirements has also led to techniques like model distillation, where a smaller, more efficient model is trained to mimic the behavior of a larger, more computationally intensive one. This allows organizations to use massive computational resources for training while still deploying models that can run efficiently on more constrained hardware.
The Efficiency Imperative
As AI models have grown larger and more computationally demanding, finding ways to use computational resources more efficiently has become increasingly important. This efficiency quest happens at multiple levels, from algorithmic innovations to hardware design to system-level optimizations (Microsoft Research, 2023).
At the algorithmic level, techniques like sparse attention mechanisms allow models to focus computational resources on the most relevant parts of the input, dramatically reducing the number of operations required. Mixed-precision training uses lower numerical precision where possible, reducing memory requirements and increasing computational throughput. Efficient architectures like MobileNet and EfficientNet are designed specifically to maximize accuracy while minimizing computational requirements.
Hardware-level optimizations include specialized instructions for AI operations, improved memory hierarchies to keep processors fed with data, and increasingly sophisticated on-chip networks to coordinate between processing elements. The co-design of hardware and algorithms has become increasingly important, with hardware designers working closely with AI researchers to create systems optimized for specific workloads.
System-level approaches focus on making better use of available hardware through techniques like model parallelism (splitting a model across multiple devices), pipeline parallelism (processing different stages of computation on different devices), and dynamic batching (grouping multiple requests together for more efficient processing). Frameworks like DeepSpeed and Megatron enable training of models that would be impossible to fit on a single device by coordinating computation across hundreds or thousands of processors.
The efficiency imperative extends to deployment strategies as well. Techniques like quantization (using lower-precision numbers for model parameters), pruning (removing unnecessary connections in neural networks), and knowledge distillation (creating smaller models that mimic larger ones) allow models trained on massive computational resources to run efficiently on more constrained hardware.
The Democratization Challenge
The exponential growth in computational requirements for state-of-the-art AI has created a significant barrier to entry, concentrating advanced AI development among a small number of well-resourced organizations. This raises important questions about access, innovation, and the future direction of AI research and applications (Stanford HAI, 2023).
Academic researchers, startups, and independent developers often lack access to the computational resources needed to train cutting-edge models from scratch. A single training run for a large language model can cost millions of dollars in compute resources alone, putting such work out of reach for all but the largest tech companies and best-funded research labs.
This computational divide has led to various efforts to democratize access to AI compute. Cloud providers offer specialized AI infrastructure that can be rented by the hour, making high-end hardware accessible without the capital investment of purchasing it outright. Research grants and academic access programs from companies like NVIDIA and Google provide computational resources to researchers working on important problems.
Open-source models and pre-trained weights allow developers to build on existing work rather than starting from scratch, significantly reducing the computational requirements for creating useful AI systems. Transfer learning techniques enable adaptation of these pre-trained models to specific tasks with relatively modest computational resources.
Distributed computing projects like Folding@home have demonstrated the potential for coordinating volunteer compute resources across many individuals. Similar approaches for AI computation could potentially create "compute commons" that democratize access to computational resources for AI development.
Despite these efforts, the gap between the computational haves and have-nots in AI continues to widen. Finding sustainable models for broader access to AI compute remains one of the central challenges for ensuring that the benefits of AI progress are widely shared.
The Scaling Debate
One of the most contentious questions in AI research concerns the relationship between computational scale and intelligence. Some researchers argue that continued scaling of computational resources and model size will eventually lead to artificial general intelligence (AGI), while others contend that fundamental conceptual breakthroughs are needed regardless of computational power (Anthropic, 2023).
The scaling hypothesis suggests that many aspects of intelligence emerge naturally as neural networks grow larger and are trained on more data with more computational resources. Proponents point to the surprising capabilities that have emerged in large language models as they've scaled up, from basic reasoning to creative writing to rudimentary coding abilities.
Skeptics argue that current approaches suffer from fundamental limitations that won't be overcome simply by throwing more computation at the problem. They point to persistent issues like hallucinations (confidently stating false information), lack of true understanding, and inability to perform reliable logical reasoning as evidence that different approaches are needed.
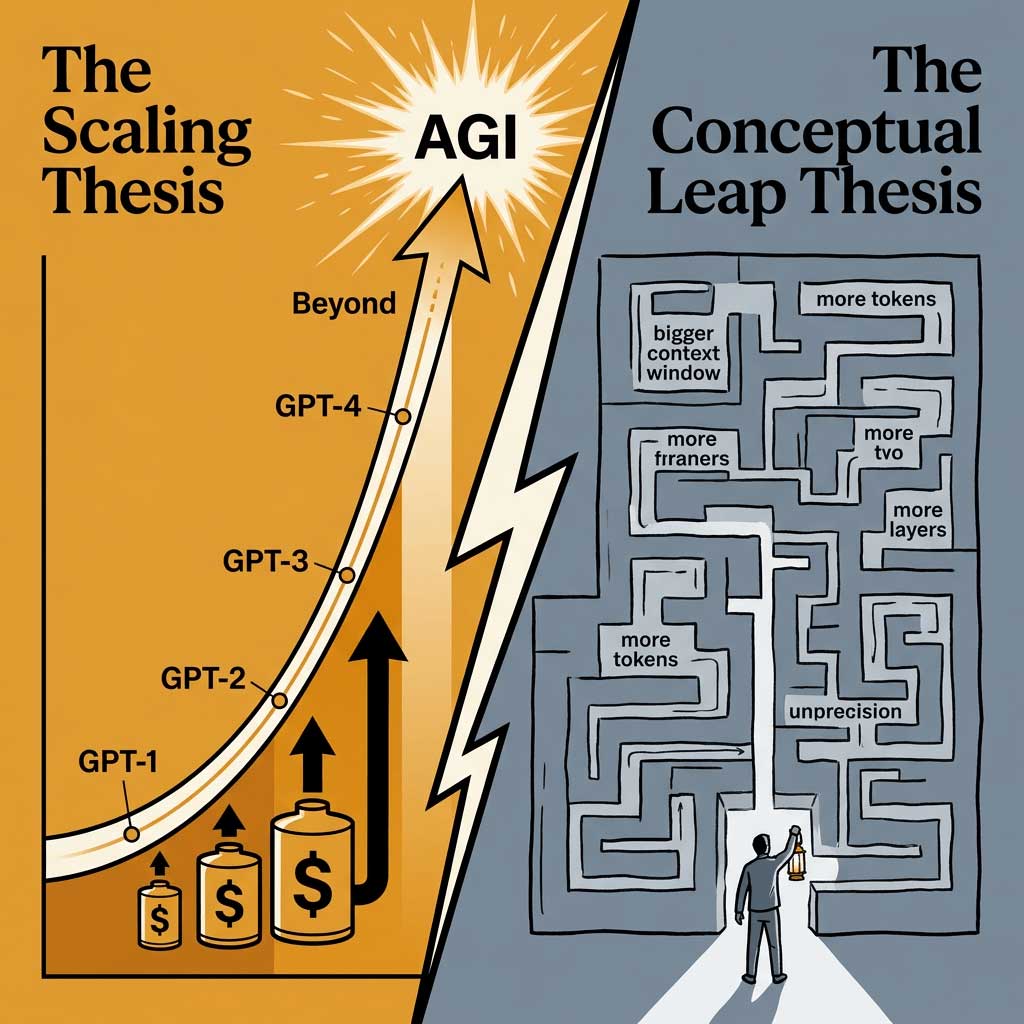
The debate has significant implications for the future of AI compute. If the scaling hypothesis is correct, then continued investment in ever-larger computational resources is a direct path to more capable AI systems. If not, then such investments may yield diminishing returns, and resources might be better directed toward exploring alternative approaches.
The reality likely lies somewhere in between these positions. Scaling has clearly enabled significant advances, but may eventually hit diminishing returns without conceptual breakthroughs. Finding the right balance between computational scaling and algorithmic innovation remains one of the central challenges in advancing AI capabilities.
The Future Computational Landscape
The future of AI compute will be shaped by a complex interplay of technological advances, economic factors, and societal choices. Several trends are likely to influence this evolution over the coming years (IEEE Spectrum, 2023).
Specialized AI hardware will continue to evolve, with increasing diversity in approaches. Neuromorphic computing systems that mimic the structure and function of biological brains may offer dramatic efficiency improvements for certain types of AI workloads. Optical computing, which uses light rather than electricity to perform calculations, could potentially overcome some of the physical limitations of traditional electronic systems.
Quantum computing, while still in its early stages, holds promise for certain AI applications. Quantum systems may eventually offer exponential speedups for specific algorithms relevant to machine learning, though practical, general-purpose quantum computers remain years or decades away.
Edge computing will grow in importance as more AI workloads move from centralized data centers to distributed devices. This shift will drive development of ultra-efficient AI hardware and algorithms designed to run with minimal power consumption and memory requirements.
The environmental impact of AI computation will receive increasing attention, driving research into more energy-efficient hardware and algorithms. Carbon-aware computing, which considers environmental impact alongside traditional metrics like speed and cost, may become standard practice for responsible AI development.
The economics of AI compute will continue to evolve, with potential for both concentration and democratization. Cloud providers may offer increasingly specialized AI infrastructure as a service, while open-source hardware designs and community compute resources could expand access to smaller players.
As AI systems become more capable and are deployed in more critical applications, reliability and security of AI compute will become increasingly important. Techniques for secure multi-party computation, confidential computing, and hardware-level security features will likely see increased adoption.
The computational foundations of AI will continue to shape what's possible, what's practical, and what's accessible in artificial intelligence. Understanding these foundations is essential for anyone seeking to navigate the rapidly evolving landscape of AI technology and applications.





